

匠心风云
在ICT领域,“扩展”(Scale)是一个高频出现的技术概念,其核心目标是提升系统处理更大工作负载的能力。当前主流的扩展方式分为两大类:纵向扩展(Scale-Up) 和横向扩展(Scale-Out),这两种技术路线在AI网络时代呈现出了协同演进的新趋势。本文将从技术定义、核心差异、应用场景及实际案例等维度展开解析。
Scale-Up 和 Scale-Out的技术定义
Scale-Up:通过为单一系统叠加资源(如增加处理器速度、内存或存储容量)来增强性能,本质是让单个系统 “更强悍”。
Scale-Out:通过添加更多同构或异构系统构成分布式架构,借助并行计算提升整体处理能力,依靠增加并行工作的独立节点数量实现扩展。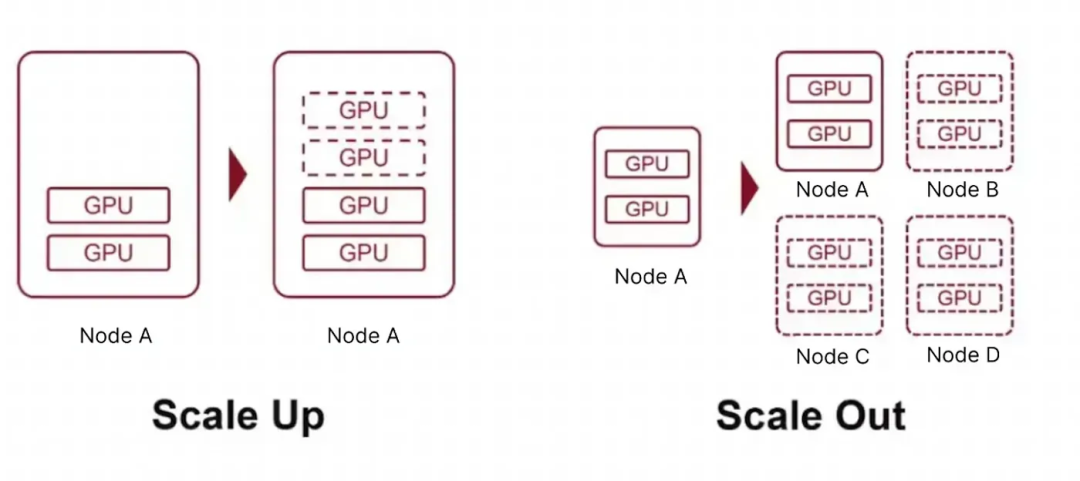 网络架构示例
网络架构示例
Scale-Up:机箱式交换机通过加装线卡提升容量;
Scale-Out:多台盒式交换机通过CLOS架构实现网络容量扩展。
在许多情况下,Scale-Up和Scale-Out可以结合起来构建更大、更高效的网络。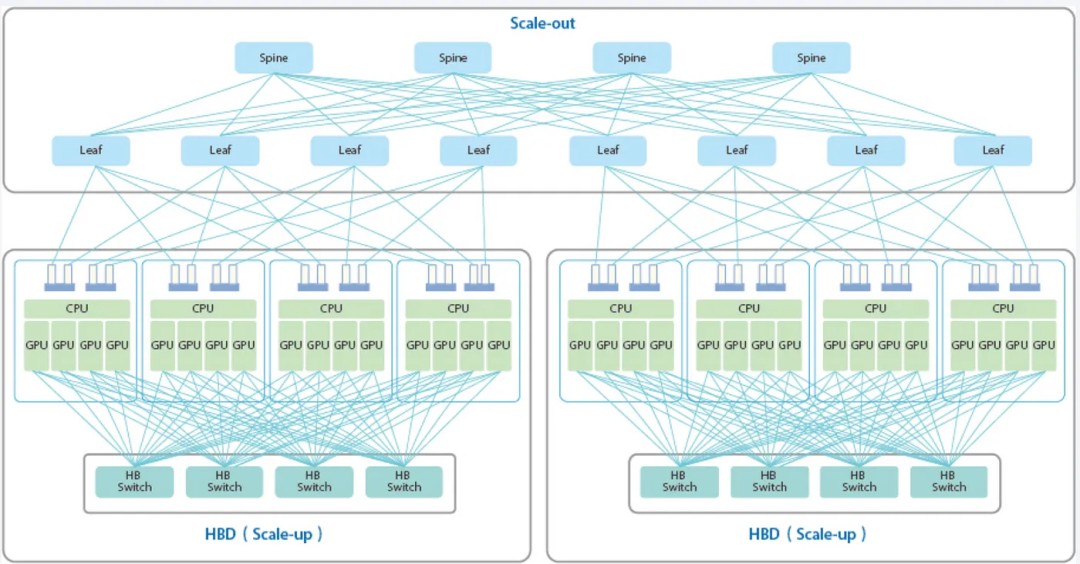 在AI计算网络中,Scale-Up网络与Scale-Out网络并存:
在AI计算网络中,Scale-Up网络与Scale-Out网络并存:
Scale-Up 是指 GPU 之间的高速互连,允许跨 GPU 内存读/写。
Scale-Out 是基于以太网/InfiniBand的RDMA(如RoCE),实现GPU间远程内存访问。
Scale-Up 和 Scale-Out 网络之间的协同作用为当今的 AIGC 大型模型提供了动力。
Scale-Up 和 Scale-Out的核心差异
虽然两者都旨在实现 GPU 间的内存级数据传输,但其设计目的和应用场景却截然不同。随着AI 大模型的兴起,计算规模持续增长。单个 GPU 服务器已无法满足需求。并行计算成为必需,这带来了通信开销、分区复杂性和编程挑战。Transformer 及其注意力机制和前馈层对内存和计算资源提出了极高的要求。
理想情况下,若存在超级 GPU 芯片可独立处理整个大模型,则无需扩展。但现实中需对模型进行拆分:
高频交互部分(如张量并行、专家并行):需要高速低延迟网络,即Scale-Up 网络(也称为负载存储或内存语义网络)。
独立并行部分(如流水线并行、数据并行):更适合采用成本效益更高、灵活性更强的方案,即Scale-Out 网络(利用以太网并优化 RDMA,如 RoCE)。
尽管 RDMA 在一定程度上模拟了内存访问,但其对频繁的小内存读写支持并不理想,并非真正的内存语义网络。这种双网络架构实现了性能与成本的平衡:Scale-Up 专注于极致性能,Scale-Out 则侧重灵活性和经济性。
在大规模模型训练中,两种网络均支持 GPU 间数据传输,但延迟差异显著。
网络延迟是指数据在网络中传输的时间,包括:
静态延迟:相对固定,由物理设计和硬件性能决定。
动态延迟:可变,受网络负载和带宽利用率影响(如通过 UEC 优化的以太网可降低动态延迟)。
Scale-Up :纳秒级延迟的极致性能
这是一个支持直接 GPU 内存访问的总线域网络。由于现代 GPU 时钟频率超过 1GHz(单周期小于 1 纳秒),超低延迟至关重要。Scale-Up网络需实现亚微秒级甚至更低的延迟。为此,其设计需深度绑定具体应用需求,摒弃传统传输层和网络层,采用信用机制流量控制(Credit-Based Flow Control)和链路层重传(Link-Layer Retransmission)保障可靠性。
同时,高速 SerDes 技术(如 PAM4 信号、112Gbps/224Gbps DSP 架构)带来了确定性延迟控制的挑战。现有 RS (544, 514) 前向纠错(FEC)方案可能在此速率下失效,需探索新的 FEC 方法以进一步降低延迟。
Scale-Out:毫秒级延迟与更高灵活性
相比之下,Scale-Out 网络天生具备更高的灵活性和多样性,其设计借鉴了 OSI 模型等传统分层网络架构,因此能支持广泛的通信和数据传输需求。尽管这种灵活性以牺牲延迟性能为代价,但也确保了网络可适应更广泛的应用场景。
在Scale-Out 网络中,端到端延迟通常维持在 1-10 毫秒,确保用户感知到系统响应的流畅性。对于 AI 和HPC中的计算密集型任务,尽管超低延迟并非必需,但稳定的低延迟仍是高性能的关键。Scale-Out 网络依托现有产业生态(如交换机和光模块),并通过 UEC和 GSE等技术优化来降低动态延迟,但由于架构本身的复杂性,静态延迟仍相对较高。
总结来看,两者的延迟目标差异显著:Scale-Up网络致力于将往返时间(RTT)从亚毫秒级降至亚微秒级,强调极致低延迟;Scale-Out 网络则优先考虑灵活性和成本效益,提供适用于广泛工作负载的毫秒级延迟。这种延迟性能的差异,正是它们在 AI、HPC 等高性能计算环境中扮演不同角色的核心原因。
Scale-Up与Scale-Out 能否统一?
由于设计理念、目标和实现方式的根本差异,将两者融合并不现实:
• Scale-Out 网络源于传统数据中心,用于连接地理分散的节点,实现高效远程通信,擅长远程传输、异构设备互联和多样化业务通信。
• Scale-Up网络是一种较新的范式,通过提升单设备性能增强系统能力,这类高度集成的网络在有限物理空间内整合资源以实现显著性能提升,且与业务逻辑深度耦合。
在 AI 和 AGI 时代,智能计算网络的需求不断升级。单纯增强传统数据中心网络的负载存储能力,或尝试用负载存储技术扩展网络,均无法满足纵向Scale-Up的需求。
两者的设计前提不同,导致技术实现、性能和成本效益存在显著差异。
从业务逻辑看,Scale-Up网络(如 NVLink)符合负载存储语义,强调直接高速内存访问;而Scale-Out网络(如 InfiniBand)基于消息语义,侧重灵活性和可扩展性。尽管某些技术规格可能看似相似,但这只是巧合,并不意味着它们具备融合或互换的潜力。
因此,由于技术理念、应用目标和业务逻辑的本质差异,Scale-Up与Scale-Out不应被强行结合,两者在各自领域均扮演着不可或缺的角色,共同推动计算网络技术的发展。
案例分析:NVIDIA NVL72 如何实现 Scale-Up 和 Scale-Out?
2024 年 3 月,NVIDIA 推出 GB200 NVL72 超级节点,将 36 个 Grace CPU 和 72 个 Blackwell GPU 集成在单个液冷机柜中,可提供最高 720 PFLOPs 的 AI 训练性能或 1440 PFLOPs 的推理性能。其架构不仅克服了 H100/GH200 等前代产品的节点间带宽瓶颈,还结合了 “GPU-GPU NVLink Scale-Up” 和 “节点间 RDMA Scale-Out”,为 EB 级数据处理和万亿参数模型训练提供了可扩展的基础设施。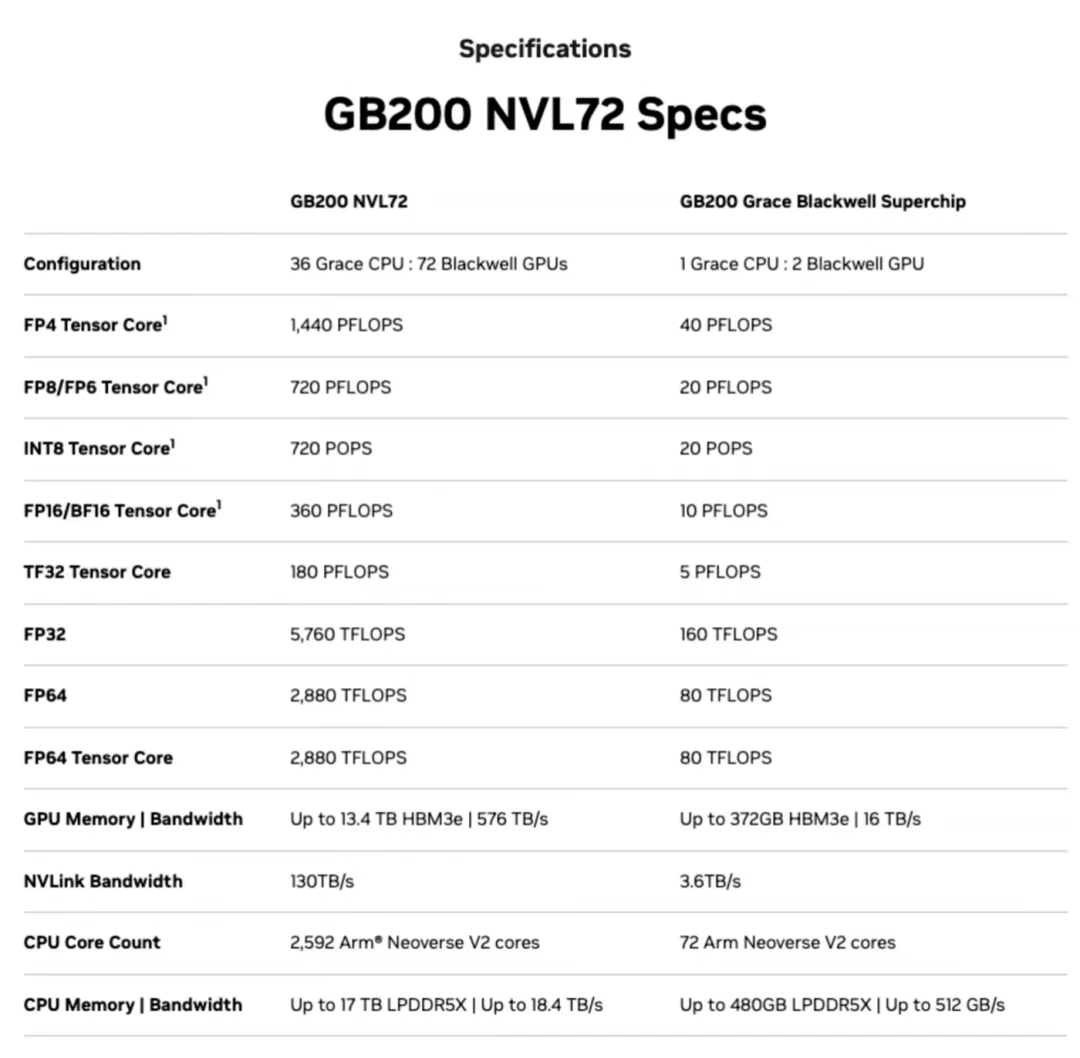
1. Scale-Up网络互连
在超级节点机柜内,18 个计算托盘(Compute Tray)中的 72 个 B200 GPU 通过 NVLink 5 和铜缆实现全互连,并连接到 9 个交换机托盘(Switch Tray)中的 18 个 NVSwitch 芯片。
理论带宽:
每个 B200 GPU 支持 1.8 TB/s 双向带宽。
每个计算托盘(4 个 GPU)提供 7.2 TB/s 总带宽,所有计算托盘合计 129.6 TB/s 双向带宽。
每个 NVLink 交换机以 7.2 TB/s 连接 4 个 GPU,一层交换机以 14.4 TB/s 连接 8 个 GPU,9 个交换机托盘合计以 129.6 TB/s 连接 72 个 GPU。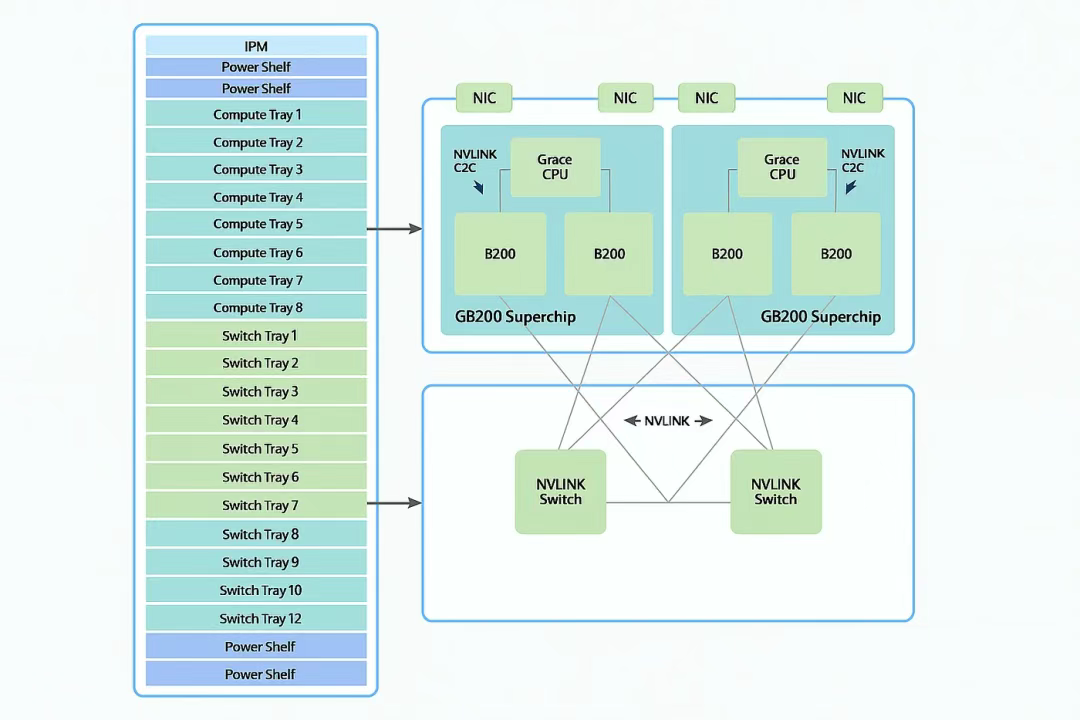
物理布线:
每个 B200 GPU 支持 18 条 NVLink 连接至 18 个 NVSwitch 芯片,实现 72 个 GPU 的全网格拓扑。
每个计算托盘(4 个 GPU)需 72 对差分线,18 个计算托盘共需 5184 对差分线,即整个机柜需 5184 根铜缆。
布线介质:
系统采用电缆盒方案(基于铜缆互连)。在短距离传输场景中,铜缆相比光模块具有更高可靠性和更低成本,且布线更简单,因此直接铜缆连接已成为Scale-Up互连的主流方案。 简而言之,NVL72 构建了大规模Scale-Up网络,实现了 GPU 间的高带宽、低延迟通信。
简而言之,NVL72 构建了大规模Scale-Up网络,实现了 GPU 间的高带宽、低延迟通信。
2. Scale-Out网络互连
Scale-Out支持将 8 个 DGX GB200 NVL72 单元集成为一个超级 POD(SuperPOD),包含 576 个 B200 GPU。每个计算托盘中的 4 个 GPU 各配备一个 CX8 800Gbps RNIC(RDMA 网卡),连接至基于 InfiniBand RDMA 的Scale-Out网络。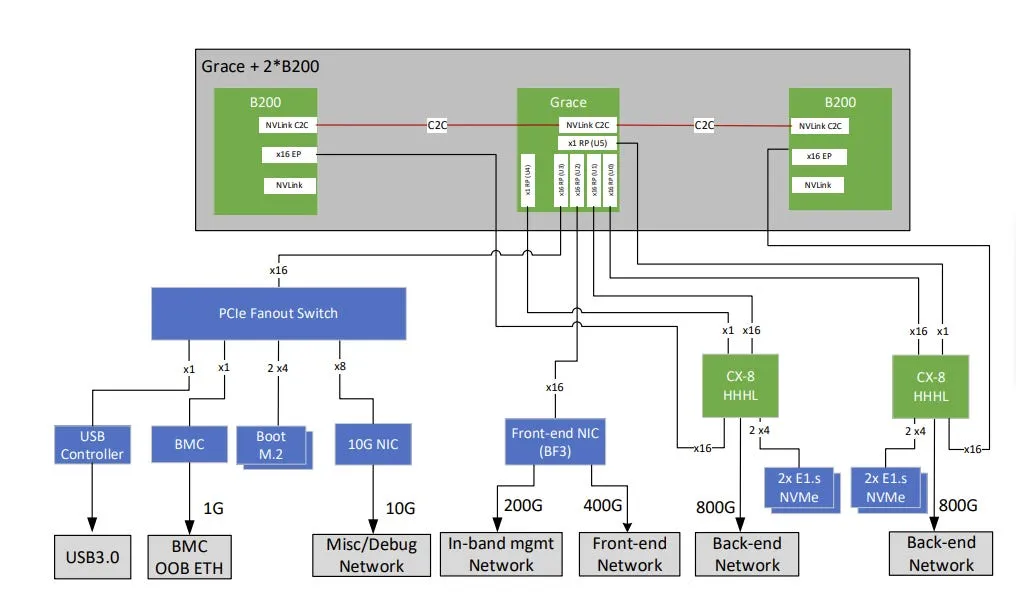
3. NVL72 中Scale-Up与Scale-Out 的对比
高带宽:每个计算托盘通过 NVLink/NVSwitch 提供 7.2 TB/s 带宽,而Scale-Out 连接仅提供 0.4 TB/s(4×800Gbps),Scale-Up带宽是Scale-Out 的 18 倍。
低延迟:铜缆消除了光模块 CDR 或 DSP 通常引入的近 100ns 延迟,同时降低了成本。
大统一内存:借助 NVLink 和 NVLink-C2C,机柜内所有 GPU 可访问彼此的 HBM 内存及 Grace CPU 的 DDR 内存,总计 13.5TB HBM 和 17TB LPDDR5X 系统内存。
总结
AI 大模型规模持续增长,对计算基础设施提出了前所未有的需求。通过Scale-Up策略构建超高性能超级节点,再通过Scale-Out 将其延伸至集群,已成为一种常见且高效的实践。这种分层架构不仅满足了现代 AI 对性能和可扩展性的需求,也为未来技术创新奠定了坚实基础。
原文链接:https://naddod.medium.com/understanding-scale-up-vs-scale-out-in-ai-infrastructure-584723afb94d
来源:SDNLAB