
Cailyn
今天凌晨5点左右,阿里巴巴宣布推出 Qwen3,这是 Qwen 系列大型语言模型的最新成员。
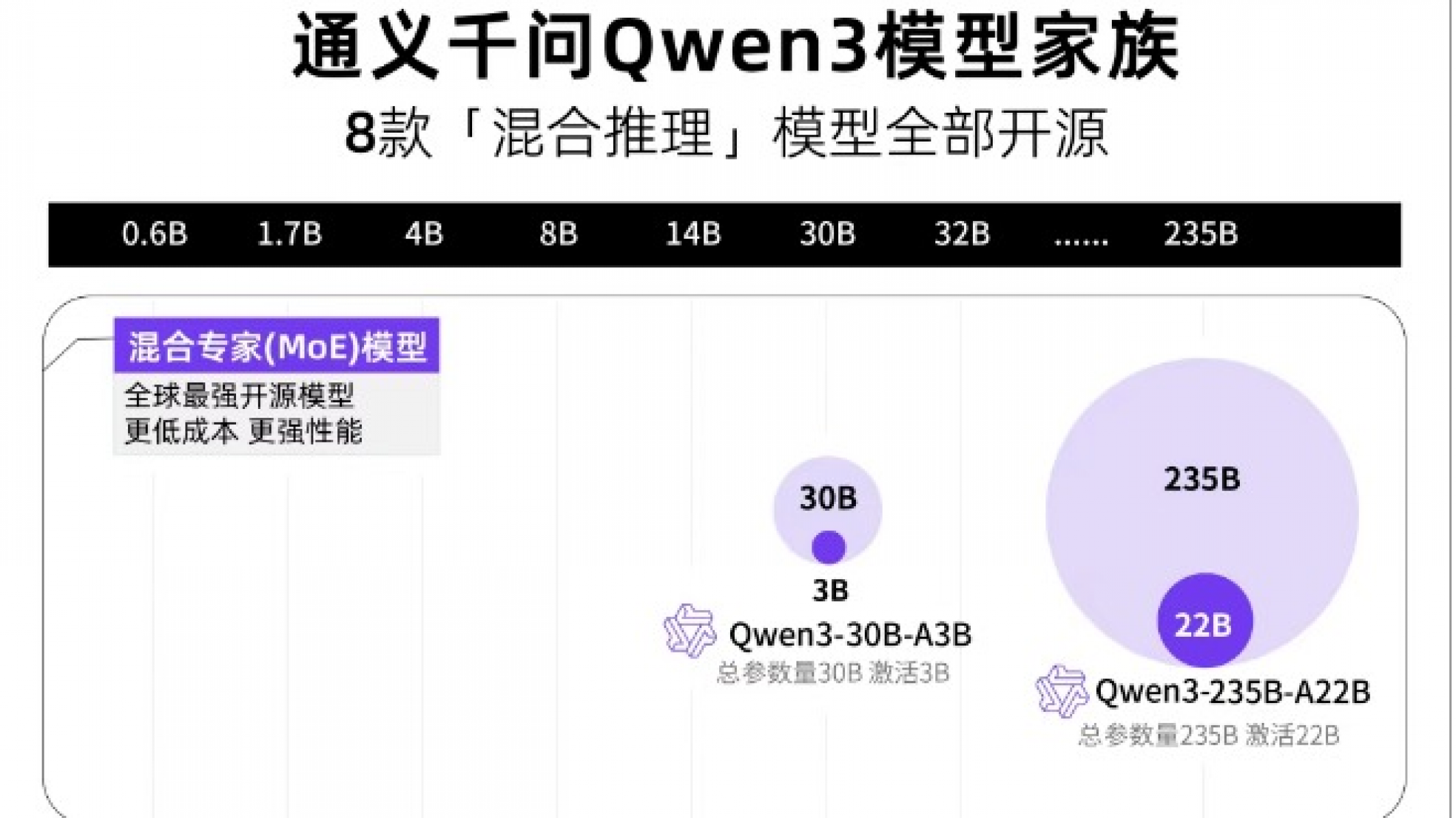
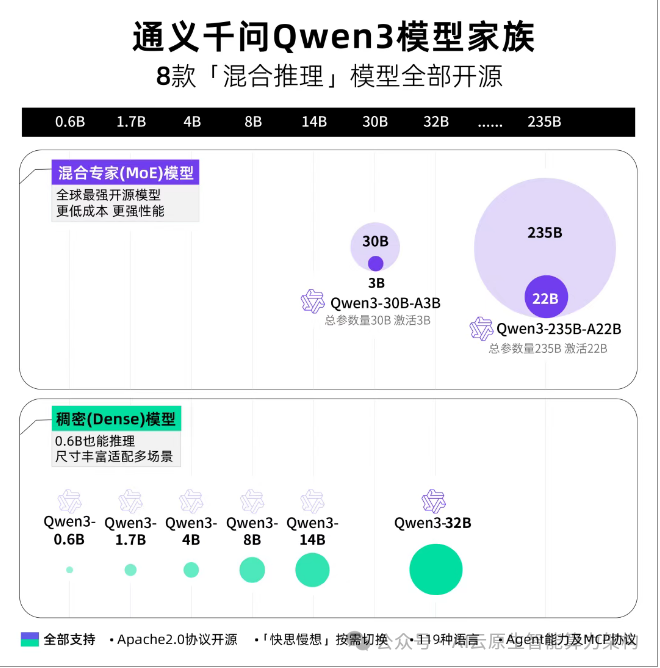
Qwen3家族包含共开源8款「混合推理模型」。均在 Apache 2.0 许可下开源。
此次开源包括:
两款MoE模型:
Qwen3-235B-A22B(2350多亿总参数、 220多亿激活参),以及Qwen3-30B-A3B(300亿总参数、30亿激活参数);
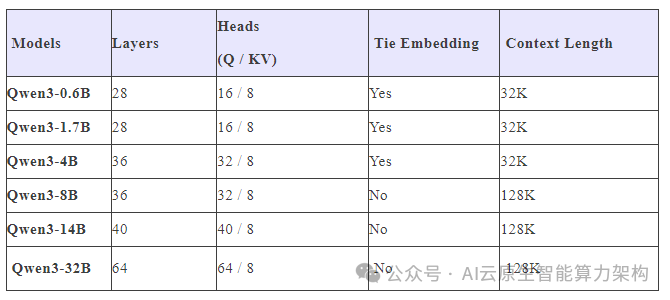
六款Dense模型:
Qwen3-32B、Qwen3-14B、Qwen3-8B、Qwen3-4B、Qwen3-1.7B和Qwen3-0.6B。
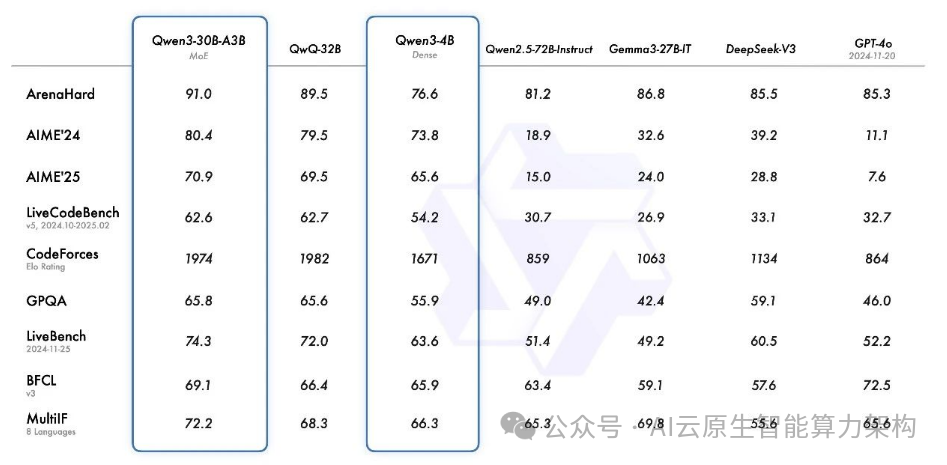
旗舰模型 Qwen3-235B-A22B 在代码、数学、通用能力等基准测试中,与 DeepSeek-R1、o1、o3-mini、Grok-3 和 Gemini-2.5-Pro 等顶级模型相比,表现出极具竞争力的结果。
此外,小型 MoE 模型 Qwen3-30B-A3B 的激活参数数量是 QwQ-32B 的 10%,表现更胜一筹,甚至像 Qwen3-4B 这样的小模型也能匹敌 Qwen2.5-72B-Instruct 的性能。
这是继 Qwen2.5 之后的重大升级,标志着国产开源模型在性能、效率和多模态能力上的全面突破。
以下从技术创新、性能表现、生态价值三个维度展开分析:
一、技术创新:混合推理架构与 MoE 技术的革命性突破
1. 混合推理架构:首次实现 “快思考” 与 “慢思考” 的无缝融合
Qwen3 是国内首个混合推理模型,将 “非思考模式”(快速响应)与 “思考模式”(复杂推理)集成于同一架构。
这种设计通过四阶段后训练流程实现:
- 长思维链冷启动:使用数学、编程等长链数据训练基础推理能力;
- 强化学习优化:通过规则奖励机制提升推理路径探索效率;
- 指令微调融合:将快速响应能力注入推理模型;
- 工具调用集成:支持 MCP 协议与外部工具动态交互。
2. MoE 架构:参数效率的里程
碑旗舰模型Qwen3-235B-A22B采用混合专家(MoE)架构,总参数 235B,但激活参数仅 22B,显存占用仅为同类模型的 1/3。
这一设计通过动态路由机制,在保持高性能的同时大幅降低计算成本。
例如:
- Qwen3-30B-A3B:300 亿总参数中仅激活 3B,性能却超越 Qwen2.5-32B(320 亿参数);
- Qwen3-4B:4 亿参数模型性能匹敌 Qwen2.5-72B-Instruct(720 亿参数)。
3. 训练体系:36 万亿 token 与四阶段优化
Qwen3 预训练数据量达 36 万亿 token,覆盖 119 种语言,较 Qwen2.5 提升 100%。训练流程分为:
- 基础能力构建:30 万亿 token 训练语言与通用知识;
- 专业能力强化:5 万亿 token 聚焦 STEM、编程等领域;
- 上下文扩展:32k 长上下文优化;
- 混合推理后训练:整合推理与非推理模式。
二、性能表现:全面超越顶尖闭源模型
1. 数学与代码能力:刷新开源纪录
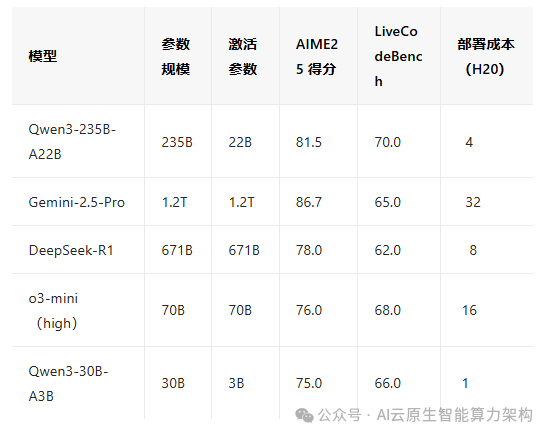
- AIME25 测评:Qwen3-235B-A22B 斩获 81.5 分,超越 DeepSeek-R1(78 分)、o3-mini(76 分),刷新开源模型数学推理纪录;
- LiveCodeBench:代码生成能力突破 70 分,超越 Grok-3(68 分),接近 Claude 3.7 Sonnet(70.3 分);
- HumanEval:在编程基准测试中,Qwen3-235B-A22B 的通过率达 78.5%,与 Gemini-2.5-Pro(79%)持平。
2. 通用能力:人类偏好与长文本处理
- ArenaHard 测评:Qwen3-235B-A22B 以 95.6 分超越 o1(92 分)、DeepSeek-R1(90 分),在人类偏好对齐上达到新高度;
- 上下文长度:支持 256k token,可处理约 50 万字的超长文本,远超 Gemini-2.5-Pro(100k)和 Claude 3.7(128k)。
3. 智能体能力:工具调用与多模态支持
- BFCL 评测:Qwen3 以 70.8 分超越 Gemini-2.5-Pro(68 分)、o1(65 分),在智能体任务中实现开源领先;
- 多模态扩展:原生支持文本、图像、音频、视频处理,可解析完整代码仓库,媲美 Gemini-2.5-Pro 的多模态能力。
三、生态价值:开源模型的全球领导力
1. 全系开源:从 0.6B 到 235B 的完整矩阵
Qwen3 开源 8 款模型:
- 稠密模型:0.6B、1.7B、4B、8B、14B、32B;
- MoE模型:Qwen3-30B-A3B(300 亿总参数)、Qwen3-235B-A22B(2350 亿总参数)。
所有模型均采用 Apache 2.0 协议,支持免费商用,且提供 Hugging Face、ModelScope 等多平台支持。
2. 成本优势:4 张 H20 即可部署旗舰模型
Qwen3-235B-A22B 仅需 4 张 H20 显卡即可部署,显存占用仅为同类模型的 1/3。相比之下,DeepSeek-R1 需要 8 张 B200 显卡,而 Gemini-2.5-Pro 的部署成本更高。
3. 开发者生态:工具链与社区支持
- Qwen-Agent 框架:封装工具调用模板与解析器,降低智能体开发门槛;
- 多语言支持:119 种语言覆盖,尤其在中文、阿拉伯语等低资源语言中表现优异。
四、与竞品对比:性能与效率的双重碾压
五、未来展望:技术路线图
Qwen3 团队计划从以下方向持续优化:
- 模型扩展:增加参数规模至万亿级,探索更复杂的推理任务;
- 多模态融合:强化视频理解与 3D 数据处理能力;
- 强化学习:利用环境反馈实现长周期推理;
- 边缘部署:优化 0.6B-4B 模型的移动端性能。
Qwen3 的发布标志着国产大模型在性能、效率、开源生态三个维度实现全面突破。
其混合推理架构与 MoE 技术不仅解决了 “大模型高成本” 的行业痛点,更通过全系开源推动了 AI 技术的普惠化。
未来,Qwen3 有望成为全球开发者构建智能应用的首选基础模型,加速 AI 在医疗、教育、金融等领域的规模化落地。
转载自AI云原生智能算力架构