

Cailyn
以下是其核心能力与技术细节的深度解析:
一、核心能力与技术突破
1. 性能表现:小参数实现大能力
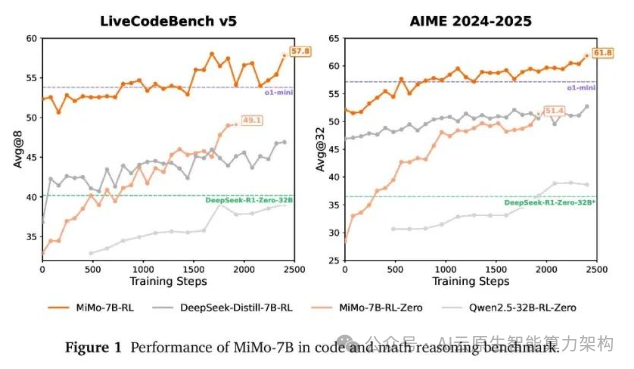
参数规模:仅 7B(70 亿)参数,却在数学推理(AIME 24-25)和代码竞赛(LiveCodeBench v5)测评中超越 OpenAI 的 o1-mini(闭源)和阿里 Qwen 的 QwQ-32B-Preview(320 亿参数)。
强化学习潜力:在相同训练数据下,MiMo-7B-RL 模型在数学和代码领域的表现显著优于 DeepSeek-R1-Distill-7B 等主流模型。
2. 核心功能
数学推理:能解析复杂数学问题,提供完整的推理路径,适用于竞赛级题目(如 AIME)和学术研究。
代码生成:支持多种编程语言,可生成高质量代码并优化算法逻辑,在代码竞赛中表现突出。
高效推理:通过架构优化和训练策略创新,在低参数下实现高推理效率,减少计算资源消耗。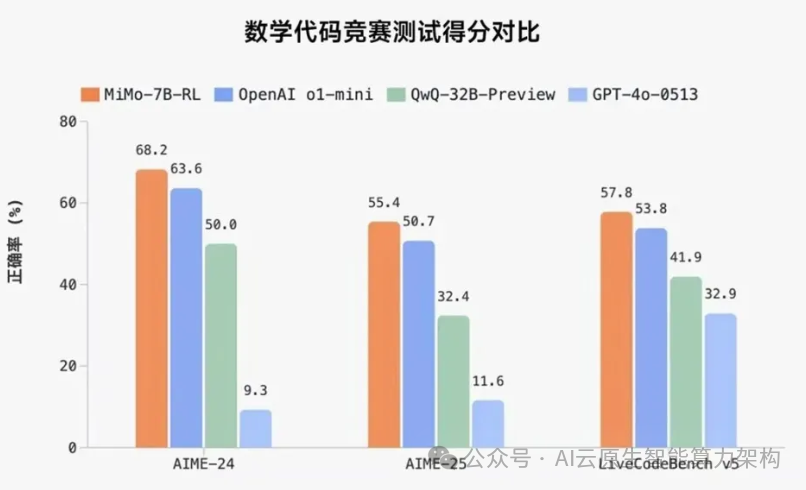 二、技术原理:数据与算法的双重创新
二、技术原理:数据与算法的双重创新
1. 预训练阶段
数据挖掘:合成约 200B tokens 的富推理语料,涵盖数学、代码、逻辑等多领域,确保模型见过更多推理模式。
三阶段训练:从简单到困难逐步提升任务难度,累计训练 25T tokens,显著提升模型对复杂问题的适应性。
2. 后训练阶段
强化学习算法:
Test Difficulty Driven Reward:将测试用例按难度分组,动态分配奖励权重,解决困难任务中的奖励稀疏问题。
Easy Data Re-Sampling:过滤低价值数据并重新采样,稳定训练过程,避免模型陷入局部最优。
训练框架优化:
Seamless Rollout 系统:通过并行计算和优化调度,将强化学习训练速度提升 2.29 倍,验证速度提升 1.96 倍。
3. 模型架构
针对推理任务优化 Transformer 架构,增强长程依赖建模能力,同时通过参数高效设计(如混合精度训练)降低计算成本。
三、开源资源与应用场景
1. 项目地址
GitHub:https://github.com/XiaomiMiMo
Hugging Face:https://huggingface.co/XiaomiMiMo
提供 4 个版本模型(Base/SFT/RL/RL-Zero)。
 技术论文:
技术论文:
https://github.com/XiaomiMiMo/MiMo/blob/main/MiMo-7B-Technical-Report.pdf
2. 应用场景
教育:辅助数学解题、编程教学,提供分步解析和代码示例。
科研:协助逻辑推理、算法验证,加速实验设计与假设检验。
软件开发:生成代码框架、优化算法,提升开发效率。
智能客服:处理复杂咨询,提供精准回答。
游戏娱乐:生成策略建议、谜题解答,增强互动性。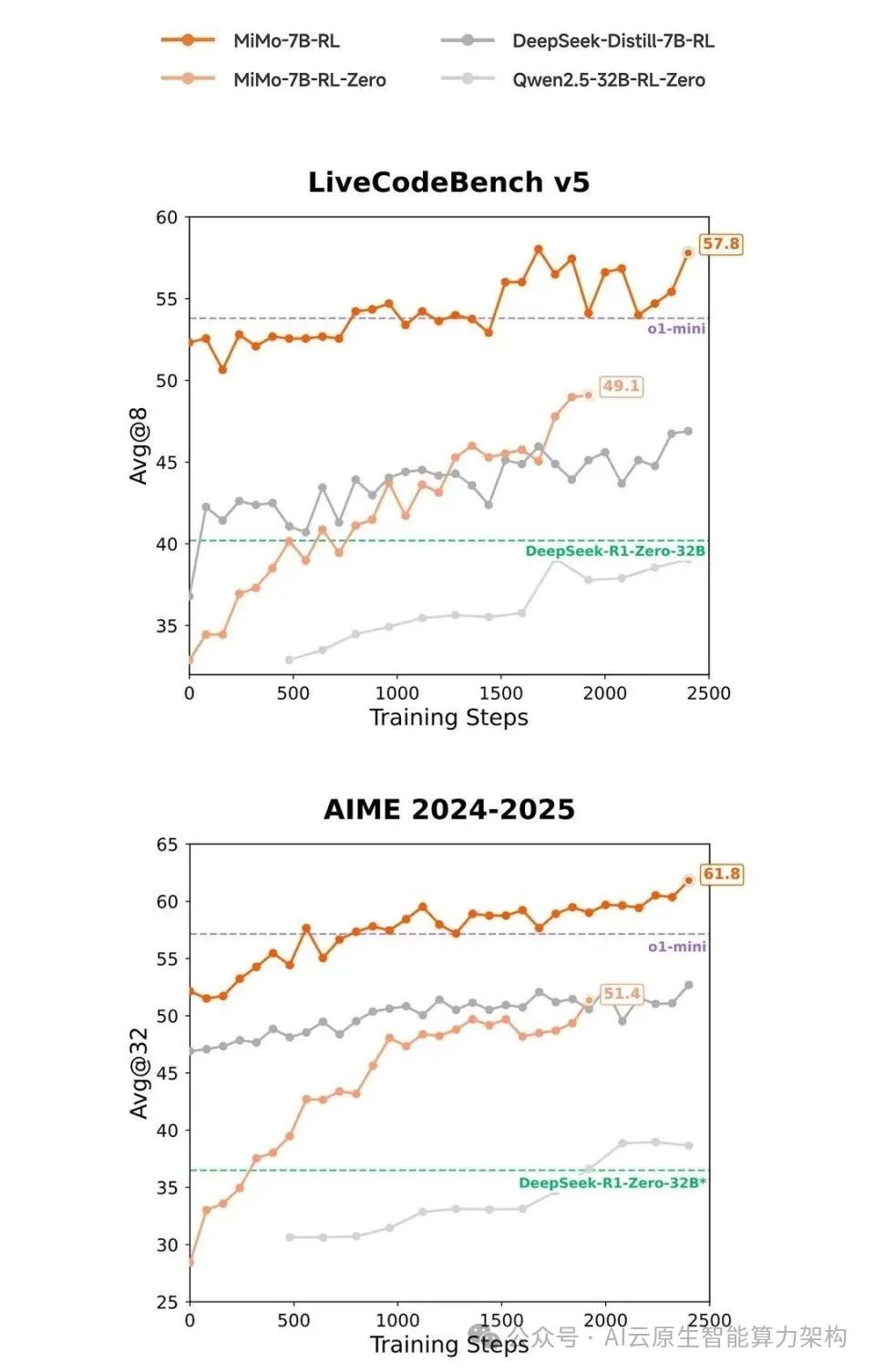 四、行业意义与未来展望
四、行业意义与未来展望
轻量化趋势:MiMo 的成功表明,通过算法创新,小模型也能实现媲美大模型的性能,为端侧 AI(如手机、物联网设备)应用提供可能。
小米的AI布局:小米正在建设万卡 GPU 集群,并引入顶尖人才(如 DeepSeek 核心开发者罗福莉),未来可能在端侧推理、多模态交互等领域持续突破。
Xiaomi MiMo 以7B 参数规模实现了推理能力的跨越式提升,其核心在于对数据质量、训练策略和算法框架的系统性优化。该模型的开源不仅为开发者提供了高效工具,也为行业指明了 “小模型大能力” 的新方向,尤其在端侧 AI 和垂直领域应用中具有广阔前景。
以下是MiMo-7B大模型技术白皮书详解
MiMo: 释放语言模型的推理潜能--从预训练到后训练
我们推出了 MiMo-7B,一款为推理任务而生的大型语言模型,在预训练和后训练两个阶段都进行了优化。在预训练阶段,我们增强了数据预处理流程,并采用三阶段数据混合策略,以增强基础模型的推理潜力。MiMo-7B-Base在 25 万亿个标记上进行了预训练,加入了多标记预测(Multi-Token Prediction)目标,以提升性能和加快推理速度。
在后训练阶段,我们策划了一个包含 130K个可验证的数学和编程问题的数据集,用于强化学习,结合了基于测试难度的代码奖励方案,以缓解稀疏奖励问题,并采用策略性数据重采样以稳定训练。大量评估显示,MiMo-7B-Base 具有卓越的推理潜力,甚至优于体积更大的 32B 模型。最终经过 RL调优的模型 MiMo-7B-RL,在数学、代码和通用推理任务中表现出色,超越了OpenAlo1-mini的性能。
具有先进推理能力的大型语言模型(LLMs),如OpenAI的o系列(OpenA1,2024)、DeepSeekRI(郭等,2025)和Claude3.7(Anthropic,2025),在数学推理和代码生成等复杂任务中取得了显著的性能。
通过大规模强化学习(RL),这些模型发展出复杂的推理模式,包括逐步分析、自我反思和回溯,从而在不同领域实现更强大、更准确的问题解决能力。
这一新兴范式代表了人工智能在应对复杂挑战方面的重大进步。
目前,大多数成功的强化学习(RL)工作,包括开源研究,依赖于相对较大的基础模型,例如32B模型,特别是在增强代码推理能力方面。
此外,人们普遍认为在一个小模型中实现数学能力和代码能力的均衡且同时的提升具有挑战性。然而,我们相信,RL训练的推理模型的有效性依赖于基础模型固有的推理潜力。
为了充分释放语言模型的推理潜能,努力不仅应集中在后训练阶段,还应关注针对推理的预训练策略。
在本工作中,我们提出了 MiMo-7B,一系列从零开始训练、专为推理任务而生的模型。我们在MiMo-7B-Base 上的强化学习(RL)实验表明,我们的模型具有非凡的推理潜力,甚至优于更大规模的 32B 模型。
此外,我们在一个冷启动的 SFT 模型上进行 RL,训练,得到 MiMo-7B-RL该模型在数学和代码推理任务中表现出色,超越了OpenAIo1-mini的性能。
核心技术突破详解:
预训练: 为推理而生的基础模型
我们优化数据预处理流程,增强文本提取工具包,并应用多维数据过滤,以增加预训练数据中的推理模式密度。我们还采用多种策略生成大量多样的合成推理数据。我们采用三阶段的数据混合策略进行预训练。
总体而言,MiMo-7B-Base在大约25万亿个标记上进行了预训练。我们将多词预测作为额外的训练目标,这增强了模型的性能并加快了推理速度。
训练后方案: 开创性推理模式
我们整理了13万道数学和代码题作为强化学习训练数据,可以通过基于规则的验证器进行验证。
每个题目都经过仔细的清理和难度评估,以确保质量。
我们仅采用基于规则的准确性奖励,以避免潜在的奖励操控。
为了解决具有挑战性的代码问题中的稀疏奖励问题,我们引入了基于测试难度的代码奖励,通过为不同难度级别的测试用例分配细粒度的分数,策略可以通过密集奖励信号更有效地进行优化。
我们实施一种数据重采样策略,以提高滚动采样效率并稳定策略更新,特别是在强化学习训练的后期阶段。
MiMo-7B 是由小米 LLM-Core 团队开发的一系列大语言模型(LLM),旨在通过优化的预训练和后训练流程,释放模型在复杂推理任务中的潜力。
1. 模型概述
1.1 概述与创新点
MiMo-78 的核心目标是提升语言模型在推理任务上的表现,尤其是在数学、代码生成及一般性推理任务中。
其创新点包括:
多任务学习: MiMo-7B 在预训练阶段引入了多样化的数据集,涵盖自然语言理解、科学问题解答、阅读理解、数学推理、编程等任务。
高效的强化学习(RL)框架: 通过“Seamless Rollout Engine”和增强的 vLLM*推理引擎,MiMo-7B 实现了高效的 RL 训练和验证。
MTP+支持: 模型集成了 MTP(Multi-Token Prediction)模块,以提高推理时的解码效率。
动态采样与早期终止机制:这些机制显著减少了 GPU 的空闲时间,提升了训练速度。
1.2 模型结构
MiMo-7B 采用了标准的 Transformer 架构,并在此基础上进行了多项改进:
GQA+(Generalized Multi-Query Attention): 允许模型在推理过程中更灵活地处理多查询任务。
Root Mean Square Layer Normalization(RMSNorm+): 作为标准化方法RMSNorm 提供了更好的训练稳定性和收敛速度。
MTP(Multi-Token Prediction): 支持多 token 预测,增强了模型在长输出任务中的表现。
2. 预训练
2.1 数据构建
MiMo-78 的预训练数据集经过精心设计,涵盖了广泛的任务类型:
自然语言理解与推理: BBH、MMLU、ARC、Hellaswag、PIQA 等基准测试。
科学问题解答: GPQA(Graduate-Level Google-Proof Q&A)和 SuperGPQA*,用于评估模型对研究生水平问题的理解能力。
数学推理: Math 和 AIME 相关数据集,专注于复杂的数学推理任务。
编程能力: LiveCodeBench、CruxEval 等数据集,用于评估模型在代码生成和执行方面的表现。
中文理解: C-Eval、CMMLU 等中文多任务基准测试。
长上下文理解: RULER 数据集,用于评估模型在长文本处理中的能力。
这些数据集的整合使得 MiMo-78 在预训练阶段就具备了广泛的推理能力基础。
2.2 训练策略
MiMo-78 的预训练采用了一个分阶段的训练策略,首先进行大规模的语言建模训练,随后逐步引入特定任务的数据,以增强模型在关键领域的表现。这一阶段的目标是让模型掌握基本的语言结构和语义表示。
2.3 评估结果
在多个基准测试中,MiMo-7B-Base 表现出色,尤其在 BBH 上取得了 75.2 的得分,展示了其强大的推理能力。此外,在 SuperGPQA 上的表现也表明该模型能够有效处理复杂的研究生级问题。
3. 后训练
3.1 监督微调(SFT)
监督微调阶段,MiMo-78 使用高质量的人工标注数据对模型进行进一步优化。这一阶段的重点是提升模型在特定任务上的准确性和泛化能力。
3.2 RL 数据整理
在强化学习(RL)阶段,MiMo-78 采用了基于难度驱动的奖励机制。具体来说,模型会根据问题的难易程度动态调整奖励函数,鼓励模型在解决复杂问题时获得更高的回报。这种机制有助于缓解稀疏奖励问题,使模型在训练过程中更有效地学习到复杂的推理模式。
3.3 RL 训练配方
MiMo-7B 的 RL 训练采用了改进版的 Group Relative Policy Optimization(GRPO)算法。该算法结合了最新的研究成果,如动态采样和 KL损失的移除,进一步提高了训练的稳定性和效率。
3.3.1 测试难度驱动的奖励机制
为了应对不同问题的难度差异,MiMo-78 引入了测试难度驱动的奖励机制。该机制灵感来源于国际信息学奥林匹克竞赛(I0I)的评分规则。每个完整的问题被划分为多个子任务,模型可以通过解决部分子任务获得相应的奖励。这种方式不仅提高了训练的效率,还使得模型能够在面对复杂问题时逐步积累经验。
3.3.2 动态采样与梯度校准
在 RL 训练中,MiMo-7B 采用了动态采样策略,即在 rollout 阶段过采样并过滤掉那些 passrate 为0或1的提示词,从而确保每次更新都基于有效的梯度。这一策略自动调整问题的难度,使得训练过程更加高效。
3.4 RL 基础设施
MiMo-7B 的 RL 训练依赖于自研的 Seamless Rollout Engine 和增强版的 VLLM 推理弓擎。这两个组件共同构成了一个高效的 RL 系统
3.4.1 Seamless Rollout Engine
Seamless Rollout Engine 是 MiMo-7B 的核心之一,它通过以下三个关键组件优化了 GPU利用率:
连续 rollout : 减少 rollout 过程中的等待时间,最大化 GPU 的使用效率。
异步奖励计算 : 在 rollout 的同时进行奖励计算,避免 GPU 空闲。
早期终止机制 : 当某个任务的奖励不再变化时,提前终止该任务,节省资源。
实验结果显示,Seamless Rollout Engine 在训练和验证阶段分别实现了 2.29x和 1.96x的加速效果。
3.4.2 vLLM-Based 推理引擎
MiMo-7B 使用 vLLM 作为推理引擎,并对其进行了多项增强:
MTP 支持: vLLM 被扩展以支持 MTP 模块,从而提高推理时的解码速度。
更强的鲁棒性: 通过清理 prefix caching 中的已计算块,保持 KVCache 的一致性;同时禁用异步输出处理以确保兼容性。
3.5 后训练评估
在后训练阶段,MiMo-78 的性能得到了进一步提升。尤其是 RL调优后的模型(MiMo-7BRL-Zero 和 MiMo-7B-RL)在数学、代码生成和一般性推理任务上表现出色,甚至超过了OpenAl 的 o1-mini 模型,
3.5.1 评估设置
MiMo-7B 在多个基准测试中进行了评估,包括:
数学推理: AIME 2025+
代码生成: LiveCodeBench v6
一般性推理: GPQA Diamond
3.5.2 评估结果
AIME 2025 : MiMo-7B-RL 达到了 55.4% 的通过率。
LiveCodeBench v6 : MiMo-7B-RL 达到了 49.3% 的通过率,GPQA Diamond :MiMo-7B-RL 达到了 54.4% 的通过率。
这些结果表明,MiMo-78 在多个领域均具备出色的推理能力。
4.1 成果总结
MiMo-78 通过优化的预训练和后训练流程,成功解锁了语言模型在复杂推理任务中的潜力。
其核心贡献包括:
高效的 RL 框架: 通过 Seamless Rollout Engine 和 VLLM 推理引擎,大幅提升了训练和推理效率。
动态采样与奖励机制: 解决了稀疏奖励问题,使模型在复杂任务中更快地收敛多任务学习:通过整合多个基准测试数据集,MiMo-78 在多个领域均表现出色。
4.2 未来展望
尽管 MiMo-78 已经取得了令人瞩目的成果,但仍有进一步优化的空间:
更大规模的模型: 随着硬件资源的进步,未来的 MiMo 系列可能会推出更大参数量的模型,进一步提升推理能力。
跨模态推理: 将视觉、音频等多模态信息集成到推理过程中,拓展模型的应用场景。
实时推理优化: 针对实际应用场景,进一步优化推理延迟和吞吐量。
MiMo-78 的开源也为社区提供了宝贵的研究资源,期待更多开发者和研究人员在其基础上构建更强大的推理模型。