
Cailyn
当 ChatGPT 掀起的生成式 AI 浪潮席卷全球,人工智能正经历着从 “工具理性” 到 “通用智能” 的范式革命。
这场革命的底层支撑,是算力芯片在架构创新、性能边界、生态构建上的持续突破。
从 GPU 单核性能提升到 HBM 与先进封装的协同创新,从海外技术垄断到国产算力生态的破局,算力芯片的演进轨迹,正深刻重塑全球科技产业的竞争格局。

一、算力芯片的技术演进:从通用计算到异构融合的范式革命
(一)GPU 架构的深度适配与生态壁垒
GPU 之所以成为 AI 算力的核心载体,源于其针对矩阵运算的深度优化架构。以英伟达 H100 为例,其采用的 Transformer Engine 专为自注意力机制设计,可动态分配 FP16/BF16 精度计算,在保持模型精度的同时提升 30% 训练速度。
这种硬件与算法的深度协同,构建了难以逾越的技术壁垒 ——CUDA 生态经过 20 年积淀,形成了包含 500 + 工具库、300 万开发者的完整体系,PyTorch、TensorFlow 等主流框架 95% 的算子依赖 CUDA 加速,构成 “硬件 + 软件 + 开发者” 的三维护城河。
然而,GPU 的性能天花板正逐渐显现。随着晶体管尺寸接近原子级别,12nm 以下制程的漏电功耗问题导致算力提升边际效应递减,倒逼行业转向异构计算架构。AMD 的 MI300X 通过集成 12 颗 Zen4 CPU 核心与 5 颗 CDNA3 GPU 核心,实现计算密度提升 8 倍,展现了 CPU+GPU+NPU 异构融合的潜力。
(二)HBM 技术:突破 “内存墙” 的关键密钥
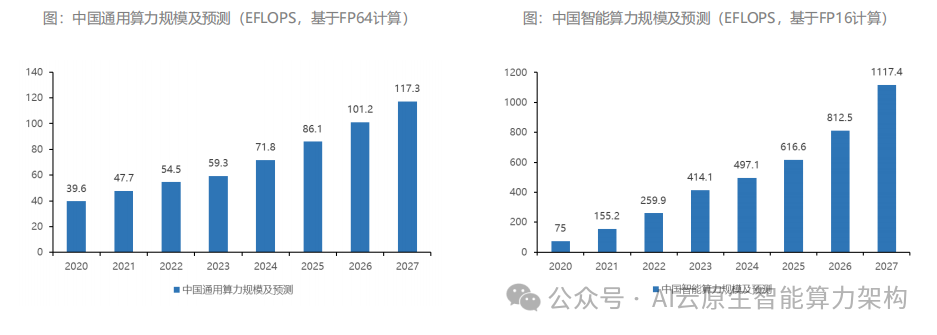
AI 模型参数规模的爆炸式增长(GPT-4 达 1.7 万亿参数),使存储带宽成为新瓶颈。传统 GDDR6 的带宽仅 600GB/s,无法满足万亿参数模型的实时调用需求。HBM 通过 3D 堆叠技术(TSV 硅通孔)将 4-12 层 DRAM 垂直集成,使单芯片带宽突破 3TB/s(HBM3),较 GDDR6 提升 5 倍以上。
这种技术创新带来的不仅是性能提升,更是计算范式的变革 —— 英伟达 H100 搭载 80GB HBM3,可在芯片内直接存储千亿参数模型,减少 90% 的数据搬运能耗。
产业链数据显示,2024 年全球 HBM 出货量达 4.9 亿 GB,同比增长 58%,SK 海力士、三星、美光三家占据 99% 市场份额。
但供应链风险同样显著:2023 年 Q4 SK 海力士 HBM3 订单已排至 2025 年,供不应求推高价格 —— 单 GB 售价达 15 美元,是普通 DRAM 的 10 倍。
(三)先进封装:连接异构算力的 “数字桥梁”
当摩尔定律放缓,先进封装成为延续 “硅基神话” 的关键。台积电 CoWoS(Chip-on-Wafer-on-Substrate)技术通过 2.5D 集成,将 HBM 与 GPU/CPU 放置在同一硅中介层,使芯片间互联带宽提升至 900GB/s(H100),较传统封装提升 10 倍。
这种技术需要突破三大难点:一是中介层制造(线宽≤5 微米),二是微凸点键合(间距≤50 微米),三是散热设计(单芯片功耗超 700W)。
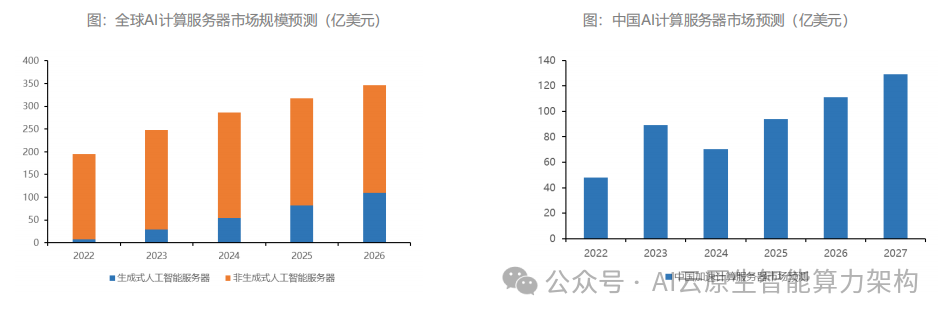
全球先进封装市场呈现寡头垄断格局:台积电 CoWoS 产能占比达 60%,支撑英伟达 80% 的高端 GPU 封装;日月光、三星分别通过 EMIB、X-Cube 技术分食剩余市场。2023 年全球 2.5D/3D 封装市场规模达 150 亿美元,预计 2028 年增至 400 亿美元,CAGR 达 22%。

二、国产算力芯片的突围路径:从技术跟随到生态破局
(一)架构创新:在细分领域建立差异化优势
面对英伟达的先发优势,国产厂商选择 “场景聚焦 + 架构创新” 策略。寒武纪 MLU370 采用混合精度计算架构,在图像识别推理场景能效比达 20TOPS/W,较 GPU 提升 3 倍,已进入商汤、旷视等企业供应链。
海光信息深算二号基于 x86 指令集与 “类 CUDA” 生态(ROCm 平台),实现对 PyTorch 的 95% 算子兼容,在互联网行业模型微调场景市占率突破 10%。
更激进的创新来自专用芯片领域。华为昇腾 910D 采用达芬奇架构,通过 3D Cube 计算单元优化矩阵运算,FP16 算力达 280 TFLOPS,支撑鹏程・等万亿参数模型训练,成为国内唯一可对标 A100 的训练芯片。
(二)生态构建:突破 “硬件易造,生态难建” 的困局
生态建设的核心是打破 “开发者锁定”。英伟达 CUDA 拥有 500 + 数学库、200 + 行业解决方案,开发者迁移成本极高。国产厂商采取 “双轨制” 策略:短期通过兼容 CUDA 降低门槛(如摩尔线程 MTT S3000 支持 CUDA 11.6 API),长期构建自主生态 —— 华为 MindSpore 已形成 “框架 - 工具链 - 硬件” 闭环,支持 50 + 大模型训练,在科学计算领域实现对 TensorFlow 的部分替代。
政府与企业协同加速生态落地。深圳、北京等地建立 “信创算力中心”,强制要求政务 AI 系统采用国产芯片,带动寒武纪、海光信息订单量年增 40%。
2024 年本土 AI 芯片在金融、能源领域的渗透率从 18% 提升至 38%,形成 “政策引导 - 场景落地 - 生态反哺” 的正向循环。
(三)产业链协同:破解 “设计强、制造弱” 的短板
国产算力芯片的最大痛点在于制造环节。中芯国际 14nm 制程良率达 95%,但 7nm 以下制程受限于 EUV 光刻机供应,与台积电存在 2-3 代差距。
突破路径在于 “Chiplet + 先进封装”:芯原微电子的 Chiplet 设计平台已实现 4 颗 GPU 芯片互联,等效算力达 A100 的 70%。
长电科技的 2.5D 封装产能预计 2024 年突破 10 万片 / 月,支持 HBM 与国产 GPU 的集成封装。
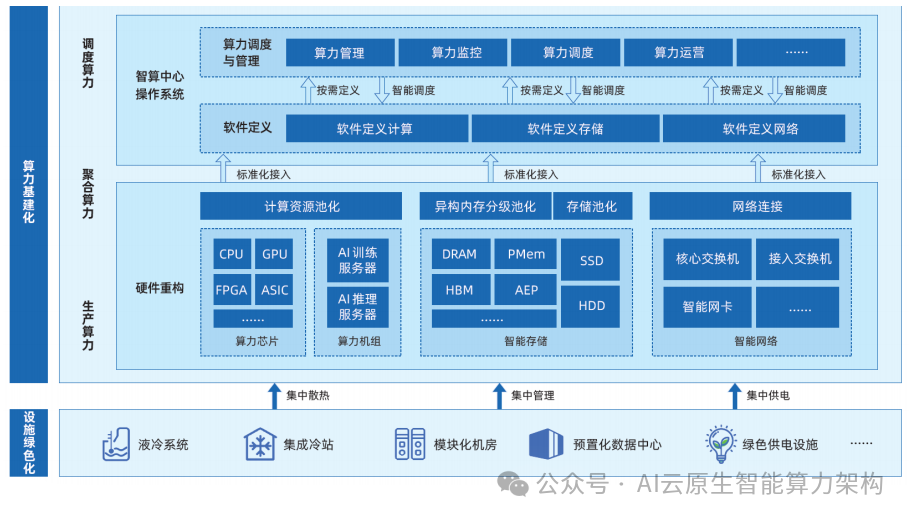
图:智算中心算力基础架构
三、未来竞争焦点:从性能比拼到体系化作战
(一)算力网络:重构全球算力资源布局
随着 “东数西算” 工程推进,中国算力基础设施正从 “分散建设” 转向 “集约化调度”。
深圳规划 2025 年算力规模达 18000 PFLOPS(FP32),通过算力调度平台实现 GPU 利用率从 30% 提升至 75%。
这种变革对算力芯片提出新要求:需支持远程集群管理(如 RDMA 技术)、动态负载均衡(如智能网卡集成),华为昇腾 Atlas 900 已实现万卡级集群的秒级故障恢复。
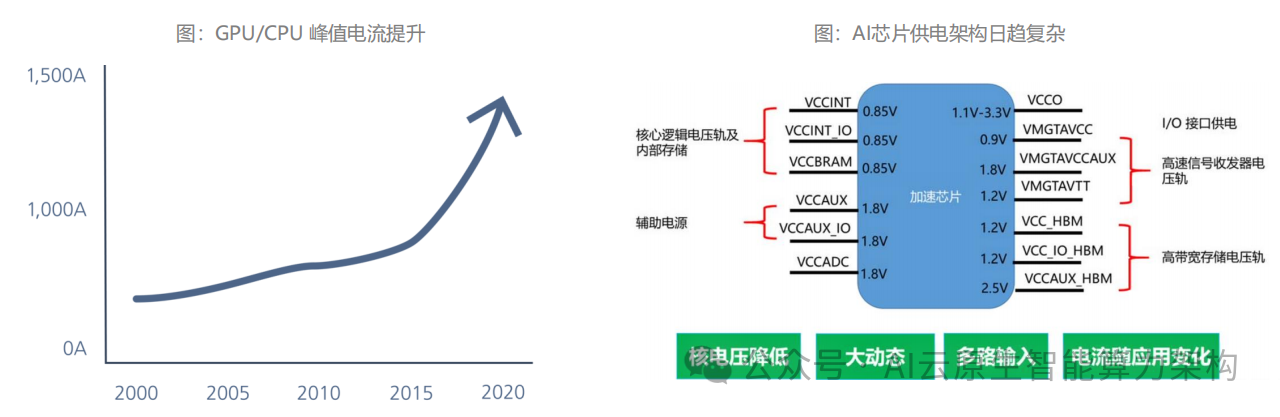
(二)绿色算力:背面供电技术开启能效革命
高算力伴随高功耗,单台 AI 服务器功耗突破 5kW,数据中心 PUE(电源使用效率)成为关键指标。
背面供电技术(BSPDN)通过将电源网络迁移至芯片背面,减少 20 层以上的金属互联,使 IR 压降从 50mV 降至 20mV,算力密度提升 44% 的同时降低 15% 能耗。
英特尔 20A 工艺已集成 PowerVia 技术,台积电 2nm 制程规划背面供电方案,国产厂商中芯国际联合希荻微开发 48V 高压供电架构,预计 2024 年实现商用。
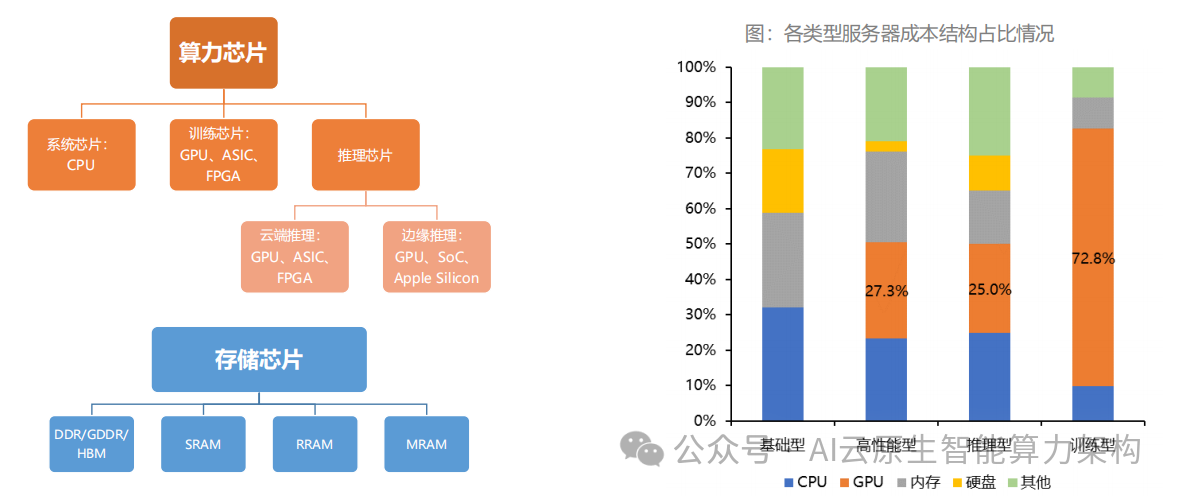
(三)算力安全:构建自主可控的产业防线
美国对 A100、H100 的出口管制持续升级,2023 年 10 月新增对 H800、A800 的限制,倒逼国内建立 “算力备胎” 体系。
从技术层看,需突破三大安全边界:芯片设计(EDA 工具国产化率提升至 30%)、制造工艺(12nm 以下制程设备国产化率达 20%)、生态安全(国产 AI 框架市场份额突破 25%)。
2023 年国家大基金二期注资寒武纪、海光信息合计 50 亿元,加速构建自主算力供应链。
在重构中定义智算时代
AI 智算时代的竞争,本质是 “技术架构 + 产业生态 + 资源调度” 的体系化比拼。当算力芯片从单一硬件升级为 “算力网络节点”,其演进逻辑已超越技术本身 —— 它既是大国博弈的战略筹码(全球 AI 算力 70% 集中于美中两国),也是产业变革的核心引擎(预计 2030 年全球算力芯片市场达 3000 亿美元)。
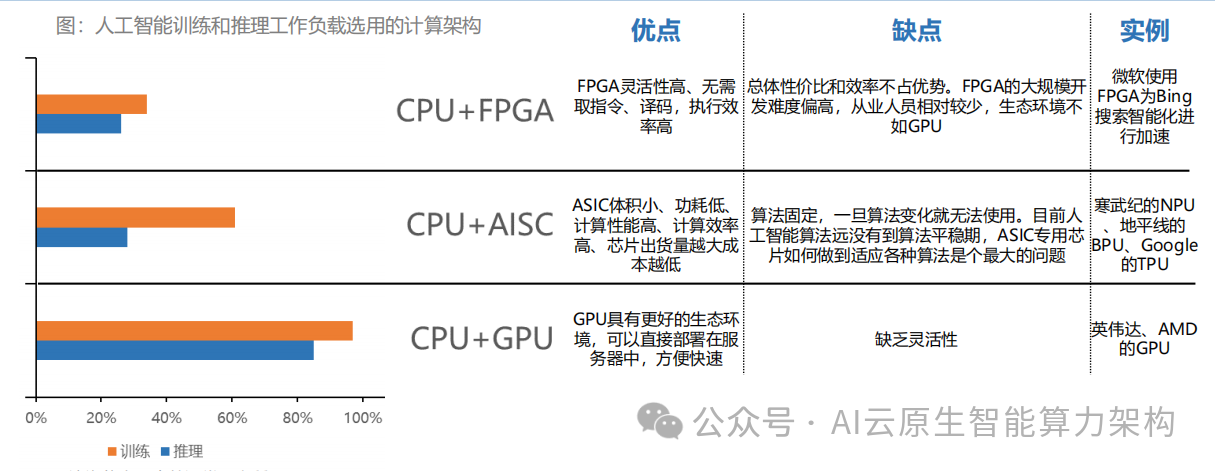
对于中国而言,突破之路在于 “双链融合”:在技术链上,通过 HBM、Chiplet、背面供电等跨代技术实现 “弯道超车”。
在生态链上,依托政府引导、场景落地、开发者培育构建自主创新体系。
当算力芯片成为数字经济的 “通用语言”,唯有掌握其核心定义权,才能在智算时代的浪潮中锚定航向,引领下一场科技革命的范式转移。