

图灵密码
字节跳动 Seed 团队推出的开源代码模型 Seed-Coder,以其 8B 参数规模在代码生成、补全、编辑及推理等核心任务中展现出超越同级别竞品的性能,同时通过创新的数据处理范式重新定义了大模型研发的 “数据基建” 逻辑。
以下是其核心技术突破与行业影响的深度解析:
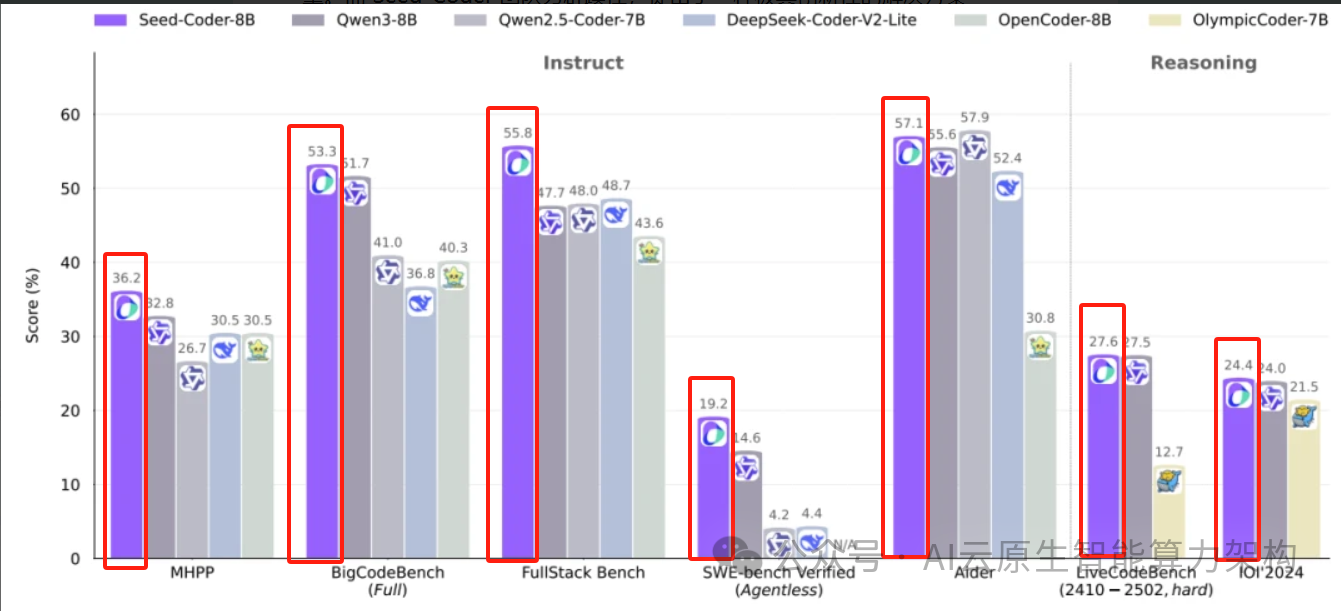
一、技术架构与性能表现
Seed-Coder 基于 Llama3 架构,结合分组查询注意力(GQA)机制,在 8.25 亿参数规模下实现了高效的推理能力。其支持 32K 上下文长度,能处理复杂的长文本编程任务,例如跨文件代码补全和大型项目逻辑推理。在多个权威基准测试中,Seed-Coder 表现尤为突出:
代码生成:在 HumanEval + 测试中,8B 模型得分 77.4,超过 70B 参数的 CodeLlama。
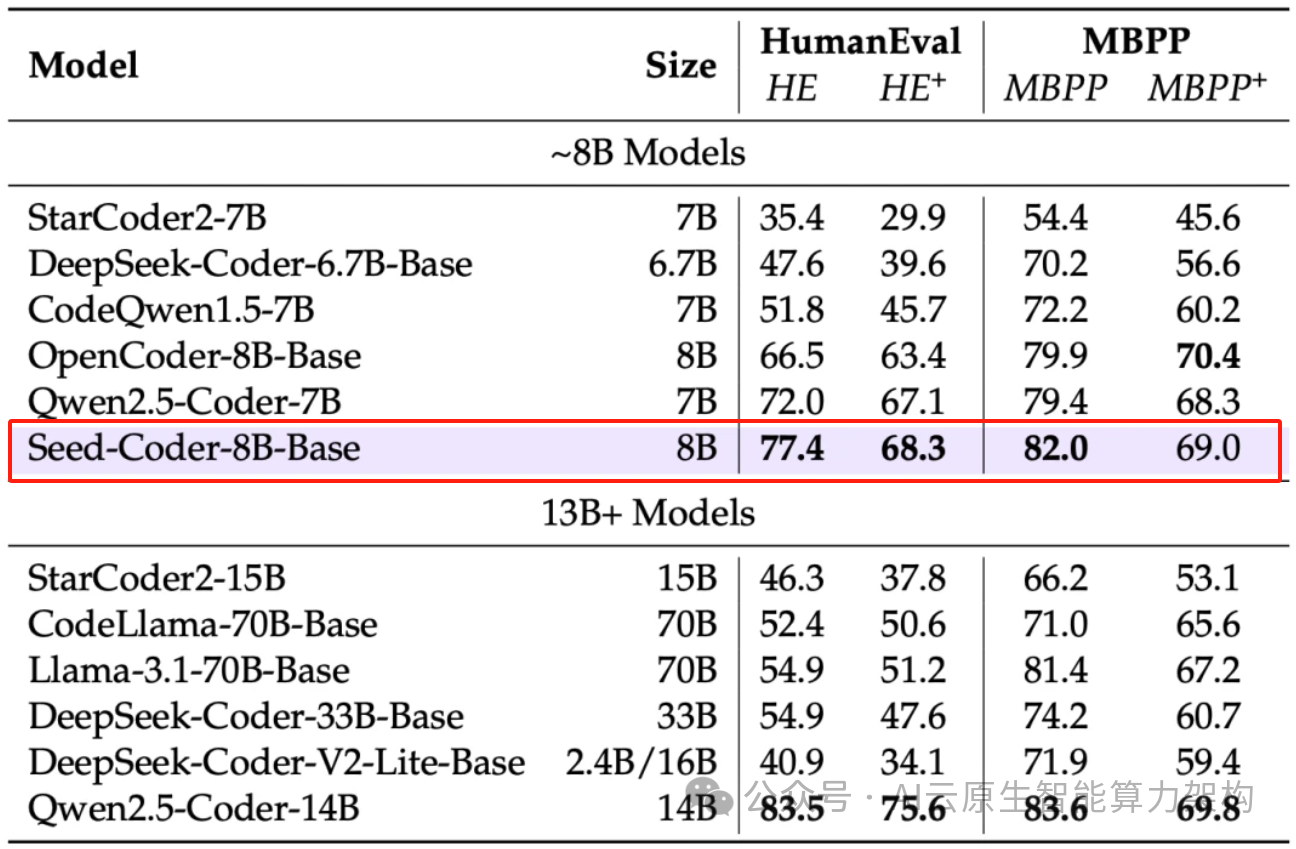
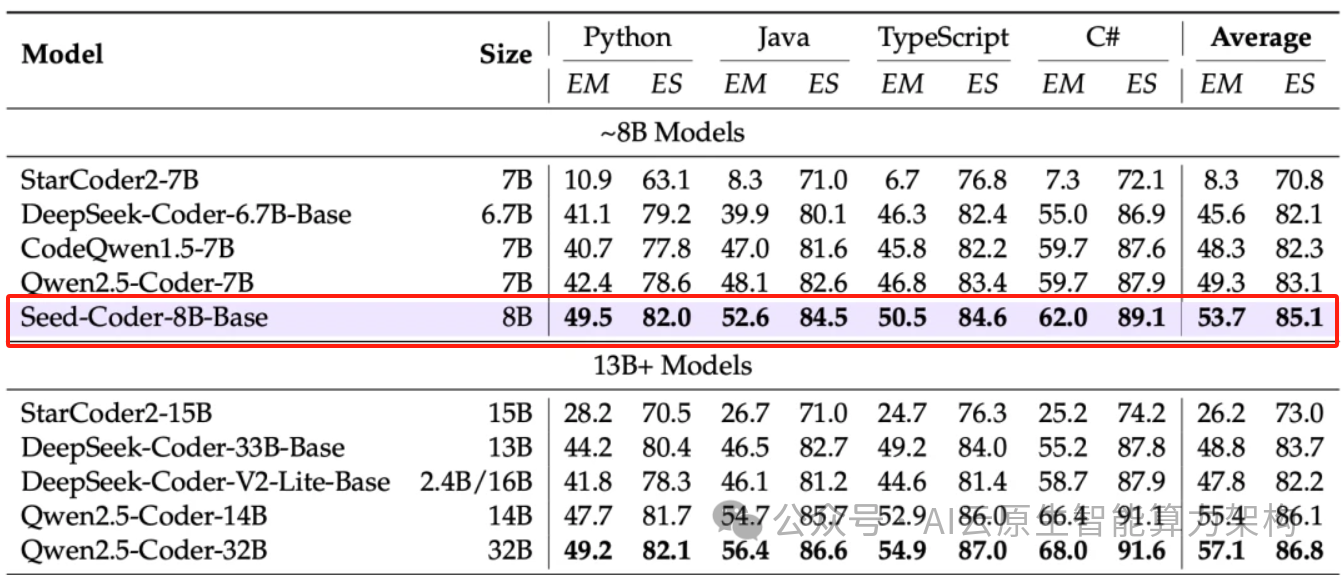
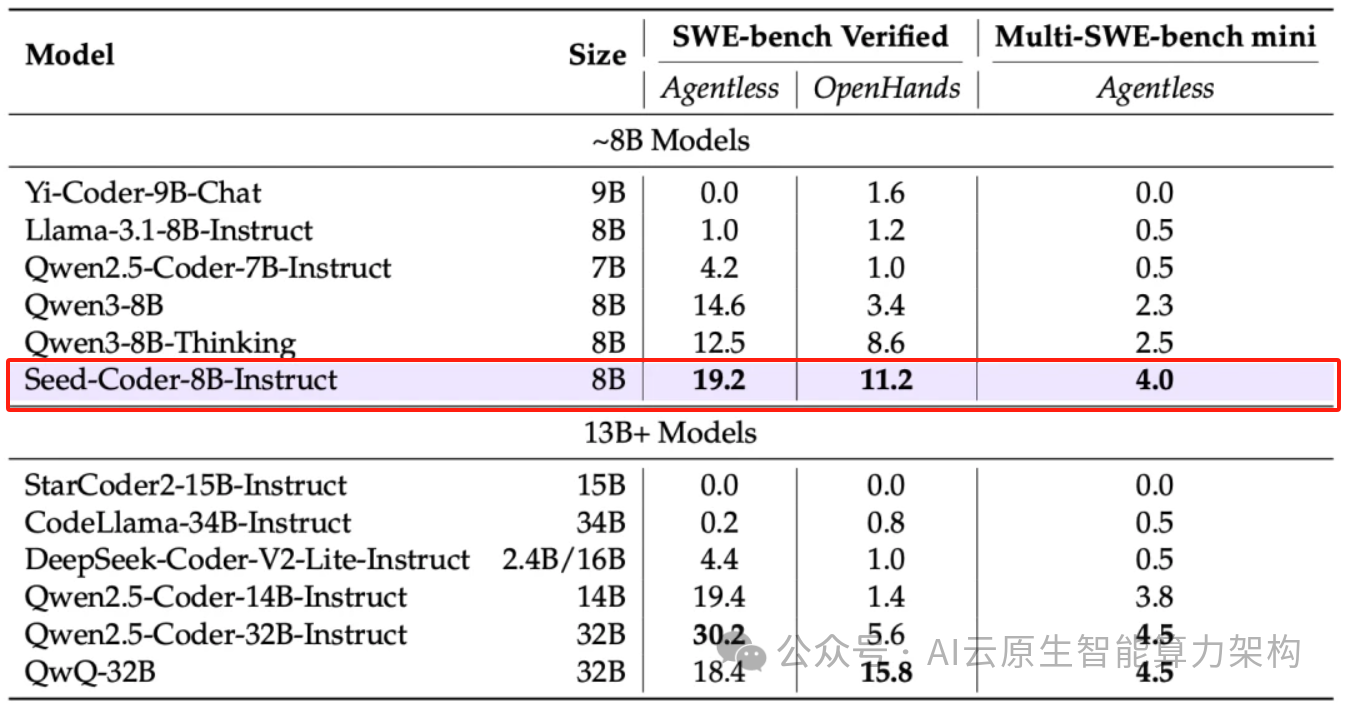
二、数据处理范式革新
Seed-Coder 的核心创新在于 “模型为中心” 的数据处理方式,通过以下步骤实现全流程自动化:
质量过滤:基于 DeepSeek-V2-Chat 训练的评分模型,从 22 万 + 份代码文档中筛选高质量数据,评估维度包括可读性、模块性、清晰度和可重用性。
提交数据优化:从 14 万个高星级 GitHub 仓库中提取 7400 万个提交记录,格式化为代码变更预测任务,生成约 1000 亿 token 的预训练语料,使模型天然具备理解代码迭代逻辑的能力。 多阶段预训练:结合文件级代码、网络数据、高质量数据集及长上下文数据,通过 Fill-in-the-Middle(FIM)和 Suffix-Prefix-Middle(SPM)训练增强上下文感知能力。
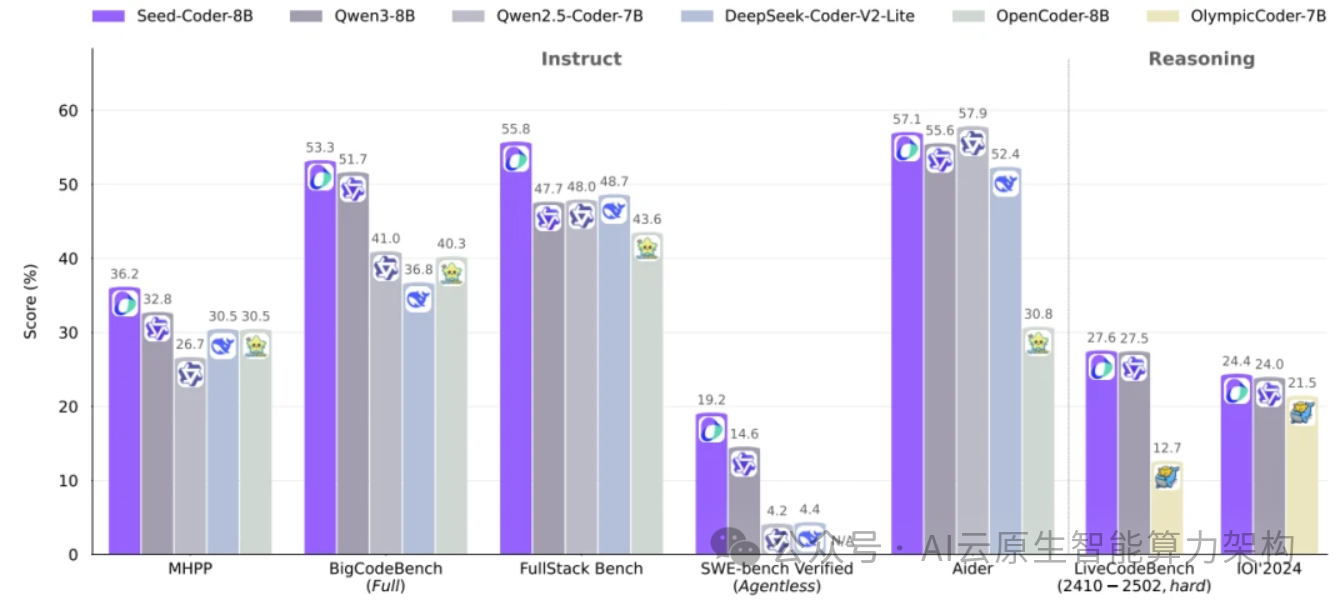
三、开源生态与行业影响
Seed-Coder 采用宽松的 MIT 协议开源,完整代码已发布至 Hugging Face,开发者可自由使用与二次开发。其开源战略具有多重行业意义:
轻量化革命:以 8B 参数超越部分 32B 模型的表现,证明通过精细化数据处理和针对性训练策略,小模型也能在垂直领域实现性能突围,为中小科技企业提供了无需堆砌算力的新路径。
数据自管理范式推广:开源的完整代码和模型,推动开发者社区围绕 “数据自管理” 思路展开二次创新,例如将类似方法应用于数学推理、科学计算等专业领域。 生态协同深化:字节跳动近期开源视频生成模型和推理模型,与 Seed-Coder 共同构建开放生态,降低 AI 开发门槛,助力开发者在自动化编程、代码审查等场景中提升效率。
四、潜在挑战与应对
尽管 Seed-Coder 展现出巨大潜力,仍需关注以下问题:
数据版权风险:数据来源包括 GitHub 等公开平台,需确保合规使用。字节跳动需进一步明确数据获取机制,例如是否获得相关授权或采用去标识化处理。
创新局限性:依赖历史数据可能导致 “数据圈套”,需通过持续引入前沿技术语料或结合动态数据更新机制,提升模型对新兴技术的适应性。 社区维护与迭代:开源模型的长期竞争力依赖社区贡献,需建立有效的开发者协作机制,例如通过技术论坛、代码贡献奖励等方式吸引生态参与。
五、未来展望
Seed-Coder 的发布标志着代码大模型从 “参数竞赛” 转向 “数据与效率驱动” 的新阶段。
其技术路径为行业提供了两点启示:
数据质量优先于规模:通过自动化数据筛选和多阶段训练,小模型可在特定领域实现性能超越,推动 AI 技术普惠化。
开源生态重构竞争格局:MIT 协议的开放策略和完整代码释放,将加速 AI 技术的跨领域应用,促进开发者社区的创新协同。
项目链接:
项目官网:https://bytedance-seed-coder.github.io
GitHub:https://github.com/ByteDance-Seed/Seed-Coder
Seed-Coder 的开源不仅是技术突破,更是 AI 行业从 “重算力” 向 “重数据与生态” 转型的重要里程碑。