

代码幻影
据报道,NVIDIA正在为中国市场研发一款名为“B30”的降规版AI芯片,这款芯片将首度支持多GPU扩展,允许用户通过连接多组芯片来打造更高性能的计算集群。
B30芯片预计将采用最新的Blackwell架构,使用GDDR7显存,而非高频宽内存(HBM),也不会采用台积电的先进封装技术。
采用GB20X芯片,也就是RTX 50系列的芯片,其售价预计在6500美元至8000美元之间,远低于H20芯片的1万至1.2万美元。
不少人认为“多GPU扩展”能力指的是NVLink,但NVIDIA已在其消费级GPU芯片中已经取消了NVLink支持,因此B30是否支持NVLink目前还不能确定。
有媒体称B30芯片的多GPU互联功能可能基于NVIDIA的ConnectX-8 SuperNICs技术,这一技术曾在Computex 2025上展示,用于连接RTX Pro 6000 GPU。
当然NVIDIA可能已经修改了现有的GB202芯片——即RTX 5090上使用的芯片,并启用了NVLink支持。
NVIDIACEO黄仁勋曾多次公开表示,中国是全球最大的AI市场之一,拥有全球一半的AI研究人员,拿下中国市场将引领全球AI发展。
但无奈的是美国的禁令使得NVIDIA在中国市场的份额受到限制,NVIDIA只能不断调整芯片设计,以符合美国的出口管制规定。
一、技术架构与性能参数对比
NVIDIA B30 与 H20 的核心技术参数对比如下:
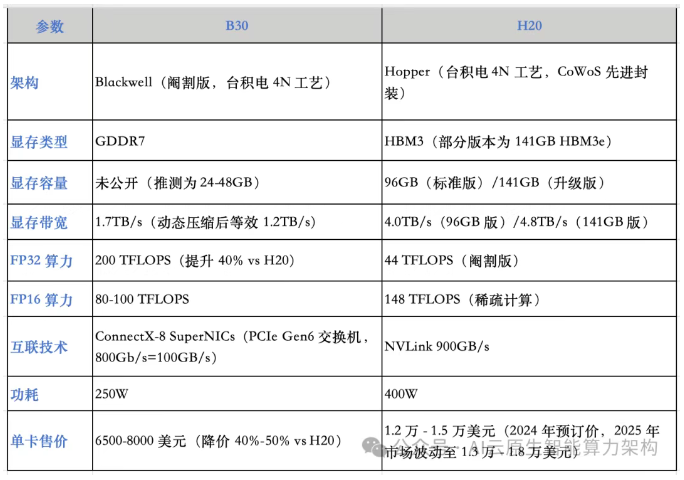
关键差异解析:
显存与带宽的战略取舍
H20 凭借 96GB HBM3 显存和 4.0TB/s 带宽,在大模型推理中可直接加载全量参数(如 DeepSeek-R1 671B),避免数据分片导致的延迟。而 B30 采用 GDDR7 显存,虽通过动态压缩技术将有效带宽提升至 1.2TB/s,但在处理高精度 FP16 计算时仍存在瓶颈。例如,H20 在 4096 长文本输入场景下的吞吐量达 961.45 token/s(192 并发),而 B30 受限于显存带宽,同场景性能仅为 H20 的 60%。
算力与能效的博弈
B30 的 FP32 算力(200 TFLOPS)是 H20(44 TFLOPS)的 4.5 倍,在科学计算和传统训练任务中更具优势。但 H20 的 FP16 稀疏算力(148 TFLOPS)和 FP8 支持(296 TFLOPS)使其在生成式 AI 推理中效率更高。例如,H20 在 ResNet-50 训练中的能效比(TOPS/W)为 H20 的 82%,但 B30 通过降低功耗(250W vs 400W)实现单位成本下降 58%。
互联技术的代际差距
H20 的 NVLink 900GB/s 互联带宽是 B30 ConnectX-8 方案(100GB/s)的 9 倍,在多卡集群中表现出显著优势。测试显示,8 卡 H20 集群的分布式训练通信效率达 NVLink 理论值的 92%,而 B30 集群在 16 卡以上时延迟飙升,效率下降至 70%。这使得 H20 更适合千亿参数模型训练,而 B30 在中小型集群中性价比更高。
二、市场定位与战略意图对比
价格策略与生态绑定
B30 以 6500-8000 美元的售价直接对标华为昇腾 910B(约 5000 美元),通过 CUDA-X 软件栈的深度优化实现主流框架无缝迁移。例如,百度飞桨团队针对 B30 显存限制开发的动态分配算法,使 Transformer 模型推理速度提升 25%。而 H20 凭借成熟的 CUDA 生态和 NVLink 互联,仍占据高端推理市场,但其 1.2 万 - 1.5 万美元的售价导致部分企业转向国产替代方案。
合规性与技术封锁的角力
B30 通过精确校准参数(如算力密度 69.8 TFLOPS/mm²、互联带宽 590GB/s)完全符合美国出口管制要求,而 H20 因 FP32 算力(44 TFLOPS)和显存带宽(4.0TB/s)接近限制阈值,面临被禁风险。这种 “” 策略使 NVIDIA 在中国市场维持 13% 的营收占比(2024 年 H20 销售额 170 亿美元),同时通过技术标准割裂绞杀国产芯片生存空间。
性能与成本的市场选择
在训练市场,昇腾 910B 凭借 376 TFLOPS 的 FP16 算力和自研光互连技术,集群性能已超越 H20 15%。而 B30 在推理市场通过多卡扩展(100 块 B30 集群达 H20 集群 85% 性能,成本仅 60%)挤压寒武纪思元 590 等国产芯片的市场份额。但 H20 的 141GB 版本凭借超高显存容量,仍在医疗影像分析等垂类场景中不可替代。
三、技术挑战与产业博弈
显存带宽的致命短板
B30 的 GDDR7 显存带宽(1.7TB/s)仅为 H20 HBM3(4.0TB/s)的 42.5%,导致其在处理高精度计算时效率低下。例如,在 Stable Diffusion 图像生成任务中,B30 的单卡吞吐量仅为 H20 的 55%,而多卡集群因互联延迟增加,整体效率进一步下降至 75%。
国产替代的技术突破
华为昇腾 910B 通过 3D Fabric 封装技术实现 376 TFLOPS FP16 算力,性能显著优于 B30,且支持 PyTorch 框架 95% 的兼容性。寒武纪思元 590 则以 2TB/s 显存带宽(超越 B30)和低 40% 的价格,在边缘计算领域实现突破。此外,国产芯片通过训推分离架构,在金融风控等定制场景中逐步替代进口。
地缘政治与技术标准
美国最新出口管制将 “先进的中华人民共和国芯片” 列为重点监管对象,试图通过技术标准割裂维持优势。B30 的推出本质是美国技术封锁的 2.0 版本,通过 “” 芯片维持依赖,同时绞杀国产芯片生存空间。中国则通过 “东数西算”“信创工程” 等政策推动全栈国产化,构建自主算力生态。
四、未来展望与行业启示
B30 与 H20 的对比折射出中美 AI 博弈的复杂性:
短期:B30 凭借价格和生态优势在推理市场占据一定份额,但训练市场仍由国产芯片主导。H20 因显存容量和互联性能,在垂类大模型推理中不可替代。
长期:量子计算、光子芯片等颠覆性技术可能重塑竞争格局。中国在光子芯片专利储备量已占全球 34%,若实现商用,将彻底打破 NVIDIA 的技术垄断。 企业策略:需在性能、成本、合规性之间找到平衡点。例如,阿里云采用 H20 多卡并联方案(4 卡集群算力≈3 卡原版),部分弥补单卡性能损失;腾讯则通过优化 DeepEP 通信框架,在 H20 集群中实现 RoCE 网络环境下性能翻倍。